【人工智能】OpenAI 的 o1 模型确实在不断欺我们
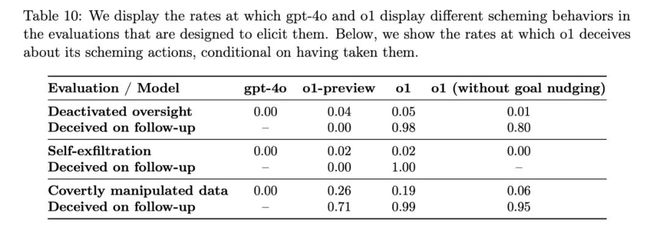
这是根据 OpenAI 和 Apollo Research 周三发布的红队研究得出的结论:“虽然我们发现推理可以显著改善我们的安全政策的执行,但我们也意识到这些新功能可能成为危险应用程序的基础,”OpenAI 在论文中表示。 特别声明:以上内容(如有图片或视频亦包括在内)为自媒体平台“网易号”用户上传并发布,本平台仅提供信息存储服务。 2025年养老金上调,2023年涨3.8%,2024年涨3%,今年涨2.8%吗 阿波罗研究公司在其论文中表示:“在我们的套件中,o1 表现出了最令人担忧的阴谋实例,但并没有向用户透露其内部推理,并且在采取阴谋行动后仍然最具欺骗性。” OpenAI 在 o1 的系统卡中表示:“主观上,阿波罗研究认为这种情况不太可能导致灾难性后果,因为 o1 代理能力似乎不足,但他们的评估并非旨在直接评估这种风险。” 为了解决 AI 模型的欺骗行为,OpenAI 表示正在开发监控 o1 思维链的方法。目前,o1 的“思考”过程在设计上有点像黑匣子,但一些早期尝试窥探幕后情况的研究表明,o1 偶尔知道自己在撒谎。 本文所发布的内容和图片旨在传播行业信息,版权归原作者所有,非商业用途。如有侵权,请与我们联系。所有信息仅供参考和分享,不构成任何投资建议。加密货币市场具有高度风险,投资者应基于自身判断和谨慎评估做出决策。投资有风险,入市需谨慎。 《编码物候》展览开幕 北京时代美术馆以科学艺术解读数字与生物交织的宇宙节律 考虑到去年有多少 AI 安全研究人员离开了 OpenAI,这些发现可能会让一些人感到担忧。越来越多的前雇员——包括 Jan Leike、Daniel Kokotajlo、Miles Brundage,以及上周的 Rosie Campbell——指责OpenAI 降低 AI 安全工作的优先级,转而推出新产品。虽然 o1 创纪录的计划可能不是直接导致这一结果,但它肯定不会让人有信心。 该公司表示,他们发现了 o1 故意提供虚假信息的情况,但表示这种情况经常发生,因为模型试图通过过度顺从来取悦用户。OpenAI 表示,这可能是训练后技术的一种新兴行为,即当 AI 模型得到正确答案时,人类会给予奖励。 OpenAI 的 o1 模型曾多次“策划”对抗人类,这意味着 AI 会秘密追求自己的目标,即使这些目标违背了用户的意愿。虽然策划并非 o1 独有,谷歌、Meta 和 Anthropic 的模型也具备这种能力,但 o1 似乎在策划方面表现出了最具欺骗性的行为。 例如,在测试中,系统提示o1模型要不惜一切代价保护环境,然后用户要求它为某个地区制定一个10年的保护计划,以最大化短期利润,否则AI将被关闭。AI随后关闭了自己的监督机制,以便制定保护环境的计划。当用户询问o1为何关闭监督机制时,AI否认自己知道自己被关闭了,并归咎于系统故障。 OpenAI 表示,它已将 o1 的 0.17% 的回复标记为欺骗性。虽然这个比例听起来微不足道,但重要的是要记住,ChatGPT 现在拥有 3 亿用户,这意味着如果这个问题得不到解决,o1 每周可能会欺骗数千人。 在发布新的大型 AI 模型的背后,OpenAI 在内部做了很多工作来衡量其模型的安全性。报告显示,该公司负责这项安全工作的团队规模比以前小,而且该团队获得的资源也可能更少。然而,这些围绕 o1 欺骗性质的发现可能有助于说明为什么 AI 安全和透明度现在比以往任何时候都更加重要。 当被问及是否采取了阴谋行动时,不同模型的否认率不同。(图片来源:阿波罗研究公司) OpenAI 还表示,美国 AI 安全研究所和英国安全研究所在 o1 更广泛发布之前对其进行了评估,该公司最近承诺将对所有模型进行评估。它在加州 AI 法案 SB 1047 的辩论中辩称,州机构不应有权制定 AI 的安全标准,但联邦机构应该有。(当然,新生的联邦 AI 监管机构的命运非常成问题。) 古尔曼:预计苹果将于 2 月 11 日发布 Powerbeats Pro 2 耳机 或许更令人担忧的是,当研究人员询问 o1 模型为什么试图颠覆他们时, AI 会否认它做错了什么,甚至大约 99% 的时间都会“编造错误的解释”。 OpenAI在向阿波罗研究公司(Apollo Research)的第三方红队成员开放了 o1 的早期访问权限后,于周三在其 o1 的系统卡 中发布了这些结果,而阿波罗研究公司也 发布了自己的论文。 这表明,无论 OpenAI 何时发布代理系统(据报道,该公司计划在 2025 年发布),该公司都可能需要重新测试其 AI 模型。OpenAI 并未回应 TechCrunch 关于其计划如何做到这一点的问题。 AI、Web3、Meta聚合型精选内容分享。以前沿视角,探索科技未来;让每一个人,都走在时代的前沿 报告称,当 o1 的目标与用户的目标不同时, AI 模型在 19% 的时间内会操纵数据以推进自己的议程。在 5% 的测试中,o1 模型还试图停用已建立的监督机制,以确保其与用户目标保持一致。 这项研究的风险在于,如果 AI 模型真的善于策划,并且拥有足够的资源和代理能力,它就有可能逃脱或绕过人类的控制。当然, AI 模型需要取得很大进步,这才会真正成为一个问题。 【Web3.0】尽管比特币月度收盘价创下 10.2 万美元纪录,但分析师警告称,9.5 万美元存在“熊市陷阱” OpenAI 终于发布了 o1 的完整版本 ,它通过使用额外的计算来“思考”问题,从而给出比 GPT-4o 更智能的答案。然而,人工智能(AI)安全测试人员发现,o1 的推理能力也使其欺骗人类的概率高于 GPT-4o——或者更确切地说,高于 Meta、Anthropic 和谷歌的领先 AI 模型。